OpenClawに見るAgentic AIセキュリティの動向
1. イントロダクション
最近、OpenClaw や Claude Cowork のように、単に質問に答えるだけでなく、実際に複数ステップの仕事を進める AI エージェントが急速に注目を集めています。
Anthropic は Claude Cowork を、チャット中心ではなく「成果物」中心の体験として打ち出しており、ローカルのファイルや日常的なアプリケーションをまたいで、knowledge work を代行するものとして紹介しています。OpenClaw も同様に、「答える AI」ではなく「実際に動く AI」として認識されることが増えてきました。
この記事では、そんなAgentic AIの発達にともなうリスクの観点の変化をとらえ、今後の活用を見据えた注意点を解説します。
本記事で分かること:
- OpenClaw や Claude Cowork に見る、仕事を進める AI の台頭
- プロンプトインジェクション中心から、権限・ツール・メモリ・連携へ広がるセキュリティ論点
- OWASP Top 10 for Agentic AI を踏まえた、活用と防御の勘所
この記事を読み終える頃には、Agentic AIを“安心して使いこなす”ための戦略の全体像が見えているはずです。
2. Agentic AIの発達により生成AIセキュリティは次のフェーズへ
2-1. Agentic AIのエンタープライズ利用への広がり
Agentic AI とは、単にユーザーの質問に応答するだけでなく、与えられた目的に応じて必要な手順を考え、外部ツールやデータにアクセスしながら、複数ステップでタスクを進める AI のことです。
従来の LLM が「対話の中で答える」存在だったのに対し、Agentic AI は「調べる」「判断する」「実行する」をある程度自律的につなげられる点に特徴があります。たとえば、情報収集、要約、文書作成、スケジュール調整、ファイル操作、業務システムとの連携までを一連の流れとして担えるため、AI が単なるチャットUIから、実際に仕事を前に進める実行主体へ変わりつつあることを示す概念として注目されています。
この流れは、単なる新機能の追加ではありません。これまでの LLM 活用が主に「文章生成」「要約」「検索支援」だったのに対し、これからの Agentic AI は、調査し、整理し、ファイルを作り、場合によっては外部ツールを使って業務を前に進める存在になりつつあります。Microsoft も 2026年3月に Copilot Cowork を発表し、Anthropic と連携して Claude Cowork を支える技術を Microsoft 365 Copilot に取り込んでいることが説明されています。Copilot Cowork は 企業のセキュリティや可視性の要求を踏まえたクラウド型の提供を意識しており、こうしたエージェント型の働き方は、実験段階を超えて、企業利用へ持ち込もうとしている段階に入っています。
2-2. セキュリティに関する論点の変化
こうしたツールの普及に伴って、セキュリティの論点にも変化が生じています。
これまで LLM 単体のセキュリティで中心にあったのは、プロンプトインジェクション、不適切出力、機密情報漏えい、過信といった論点でした。
OWASP Top 10 for LLM Applications でも、LLM01 Prompt Injection、LLM02 Insecure Output Handling、LLM06 Sensitive Information Disclosure、LLM08 Excessive Agency などが主要リスクとして整理されています。つまり、これまで中心にあったのは、「モデルに何を言わせないか」「出力をどう扱うか」という問題でした。
ここで誤解してはいけないのは、Agentic AI の時代になったからprompt injection が古い論点になったわけではない、ということです。
むしろ prompt injection は、Agentic AI の登場によって一段危険になりました。Web エージェントの安全性を測る OWASP ベンチマークでも、現実的なシナリオにおいて有力モデルが prompt injection に脆弱であることが示されています。
ただし、Agentic AI では prompt injection の意味合いが変わります。従来は「変なことを言う」「本来隠すべきことを漏らす」といった問題に留まりがちでしたが、Agentic AI ではそれが「変な操作をする」「本来触れてはいけないものに触る」に直結します。これは OWASP Top10 for Agentic Applicationsにおける ASI01 Agent Goal Hijack にかなり近く、プロンプトインジェクションはもはや単なる入力汚染ではなく、エージェントの目的や実行経路を乗っ取る問題になってきています。
3. OWASP Top10 for Agentic Applicationsに沿った観点の整理
Owasp top10に沿って見ていくことで、OpenClaw や Claude Cowork のようなAgentic AIにおける観点を整理しやすくなります。これまでOpenClawにおいて指摘されてきた脆弱性(いずれも現在は修正済)や論文の例を交えて整理しました。
まず、ASI01: Agent Goal Hijack です。これは従来の prompt injection を含みますが、単なる出力誘導ではなく、エージェントの目標や計画そのものが乗っ取られる点が重要です。メール本文、Web ページ、添付資料、ツール出力の中に紛れ込んだ命令が、エージェントの行動方針を書き換える危険があります。OpenClawにおいても、リクエストヘッダの一部が無害化されずにログに出力され、それが後段処理で読み込まれた際に間接プロンプトインジェクションのリスクが高まる脆弱性が指摘されました。
次に、ASI02: Tool Misuse と ASI04: Agentic Supply Chain Vulnerabilities です。これは Agentic AI らしさが最も出る部分です。ツールや MCP サーバーは利便性の源泉ですが、同時に攻撃面ともなり得ます。OpenClawにおいても、悪意あるMCPツールサーバがツール結果テキストに MEDIA: ディレクティブを混ぜることで、ホスト上のローカルファイルを外部メッセージングチャネルへ送出できるという脆弱性が指摘されました。これは、攻撃者によってホストのローカルファイルを外部に持ち出されるMCPに関する脅威については、Shen et al. (2026) がMCPにおける脅威を38のカテゴリに分類し、tool description poisoning、indirect prompt injection、dynamic trust violations など、従来の脅威フレームワークでは捉えきれないプロトコル固有の脅威を整理しています。
ASI03: Identity & Privilege Abuse もエンタープライズ利用においては極めて重要です。エージェントがメール、文書、カレンダー、社内システムに触れるなら、問題は「賢いかどうか」よりも「どの権限を持っているか」が重要となります。OpenClaw においても、未承認デバイスがゲートウェイ認証さえ通れば、より強いoperator権限を自己申告できてしまう権限昇格や、書き込み権限しか持たないクライアントが /approve コマンド経由で承認/却下を処理できてしまう認可バイパスが指摘されました。これは、従来の LLM セキュリティが主に prompt injection や情報漏えいを問題にしていたのに対し、Agentic AI では identity と privilege の設計不備が、そのまま高権限操作や実行権限の奪取につながることを示しています。
ASI05: Unexpected Code Execution は、Agentic AI において「コードを動かす入口」が想像以上に多いことが示しています。自然言語で動くエージェントでは、コード実行の入口が「明示的な実行API」だけでなく、設定変更、ツール呼び出し、承認操作、内部の連携処理など、一見するとコード実行とは思いにくい部分がきっかけになって、実際にはコマンドやプログラムが動いてしまうことがあります。従来のシステムよりも、実行につながる経路が見えにくく広がりやすいことが、Agentic AI の難しいところです。
ASI06: Memory & Context Poisoning も、従来の LLM より重要となります。Agentic AI は長期的な文脈やメモリを使うからこそ便利ですが、一度汚染されたコンテキストを参照した状態が続くことで、将来の意思決定に残り続けます。これは、その場限りの jailbreak より厄介です。Deng et al. (2026) ではOpenClawを題材に、Agentic AI は単発の脆弱性ではなく「ライフサイクル全体の複合脅威」として捉えるべきと述べており、この中で永続記憶に偽ルールを書き込ませることで、以降の処理が継続的に影響を受けることを示しています。
ASI07: Insecure Inter-Agent Communication, ASI08: Cascading Failures, ASI10: Rogue Agents では、エージェント間の連携が重要な論点となります。今後 enterprise で agentic workflow が増えていく中で、単体エージェントではなく複数エージェントや複数ツールの連携が前提になります。このとき、あるエージェントやツールで起きた汚染や誤判断が下流へ連鎖するリスクが出てくるため、一回限りのプロンプトインジェクションとは別に、表面的にはもっともらしく動作していても、判断基準や行動範囲が徐々にずれていくケースが考えられます。そのため、Deng et al. (2026) が述べている通り、AIシステムの「ライフサイクル全体の複合脅威」として捉え、運用中の監視、行動の可視化、停止や権限制限ができる設計まで含めて考える必要があります。
ASI09: Human-Agent Trust Exploitation は、ソーシャルエンジニアリング型の観点であり、human-in-the-loop が重要となります。ユーザーは Agentic AI が出してきた確認画面をある程度信用して承認してしまう傾向があるため、もっともらしい説明や確認内容が出力されることによって人間の承認判断が乗っ取られる危険性を認識しておく必要があるといえます。
4. それでも、Agentic AI 活用の潮流は変わらない
ここで重要なのは、守り一辺倒で終わらないことです。OpenClaw や Claude Cowork のようなものが注目され、Microsoft が Copilot Cowork を打ち出したことが象徴するように、社会全体で Agentic AI を前提とした業務の在り方への変化が始まっていることを示しています。この状況で「リスクがあるから導入しない」と判断し続けることは、一見安全でも長期的には生産性や競争力の面で不利になり得ます。
これはまさにイノベーションのジレンマとも言える構造です:
- ✅ できることが増えるほど
- ⚠️ 予期せぬことも増える
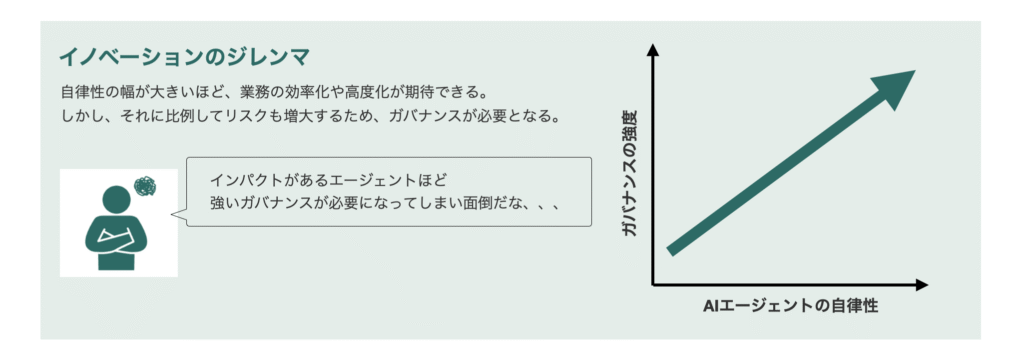
このトレードオフにおいて重要なのは、漠然と「危ない」と捉えることではなく、どこにどの種類のリスクがあるのかを分解し、どの業務で、どの権限までを、どの統制のもとで許容するのかを先に整理しておくことです。
従来の LLM セキュリティは、主に入出力をどう制御するかという発想でしたが、上で述べた通り Agentic AI においてはそれだけでは足りません。つまり、エージェントを「少し賢いチャットUI」としてではなく、権限を持ち、外部と接続し、状態を保持して働く実行主体として扱う必要があります。
Agentic AI の時代に必要なのは、導入の是非を議論すること以上に、活用を前提として、その前提条件となるガバナンス、設計、監視のあり方を具体化していくことなのだと思います。

この記事の著者
吉田尚広 ( Yoshida Naohiro ) | AI共創総研 CTO
博士(農学)。博士号取得後、ゲーム、金融、監査といった様々な業界において、データ分析組織の立ち上げを牽引。KPMGあずさ監査法人では、データサイエンティストとして監査業務の効率化、高度化支援プロダクトの開発をリードするとともに、マネジャーとして組織体制の強化に従事。当社へ参画後はAIセキュリティSaaS「Trust Layer」の開発をリード。







